
随着全球AI战略的深入推进,大语言模型(LLM)在提升生产力的同时,也引入了新的安全风险。根据OWASP发布的LLM应用十大安全威胁,提示词注入(Prompt Injection)和敏感信息泄露位列榜首,已成为企业级AI应用面临的最严峻挑战。大模型(LLM)本质上是概率生成系统,天然存在以下风险,LLM安全网关的核心目标是拦截有害输入、保障系统合规可控:
| 问题类型 | 具体表现 |
|---|---|
| 有害内容生成 | 暴力、色情、歧视、自伤等内容 |
| 提示词注入(Prompt Injection) | 恶意指令混入上下文劫持模型行为 |
| 数据外泄(企业场景) | 用户将内部敏感数据发送给外部模型 |
因为输入的提示词是自然语言,传统方案(关键词黑名单、正则表达式、决策树)在 LLM 时代面临结构性失效, 目前业界普遍使用NLP 模型去检测异常提示词,比如微调BERT模型,规则引擎没有消失,而是退化为最后一道硬性兜底(如法规关键词、证件号码正则),小模型承担高频、高速的语义分类,大模型偶尔介入高风险的复杂歧义场景。三者分工协作,才能在安全性、性能、成本之间取得平衡。
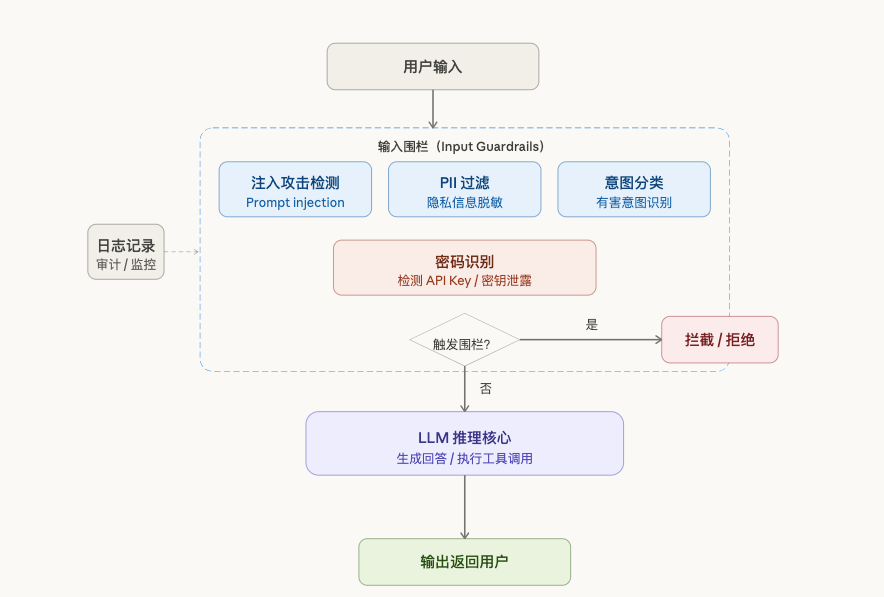
目前提示词注入检测和 意图检测是使用BERT模型检测,这个已经在前文写过了, 个人身份信息检测用的Presidio + spaCy , 这两者通常出现在 NLP 文本处理流水线中,代表两种不同的文本理解范式,在LLM安全网关、意图识别、NER(命名实体识别)等任务里经常被对比选型。BERT模型 基于 Transformer 双向编码器的深度语义理解模型,核心是上下文感知的稠密向量表示, 典型使用场景就是文本分类(有害/无害、情感、意图)。 spaCy 模型是基于规则 + 统计机器学习的工业级 NLP 流水线工具,核心是符号化、结构化的语言处理, 目的快速提取关键词、实体(人名、地名、机构名)。
Presidio 是微软开源的一套 PII(个人隐私信息)检测与匿名化框架,专为企业级数据隐私保护设计。Presidio 由两个核心模块组成:Analyzer(检测 PII)和 Anonymizer(对检测结果执行匿名化操作)。二者解耦,可以独立使用。
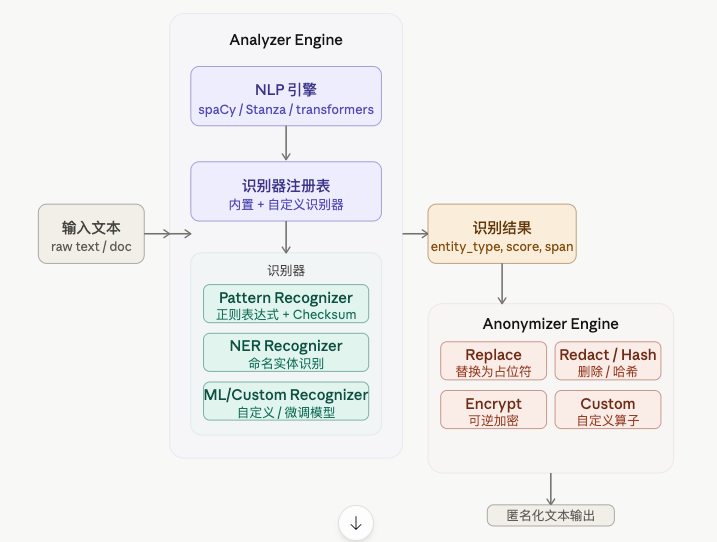
一, Analyzer Engine — PII 识别核心
-
- NLP 引擎
Presidio 本身不做 NLP,而是通过适配层对接主流框架:
- spaCy(默认):轻量、快,适合生产环境
- Stanza:斯坦福 NLP,精度更高
- Hugging Face Transformers:支持 BERT/RoBERTa 等预训练模型做 NER
NLP 引擎负责分词、词性标注、命名实体识别(NER),为下游识别器提供语言学特征。
-
- 三类识别器
| 识别器类型 | 原理 | 典型用途 |
|---|---|---|
| Pattern Recognizer | 正则 + Checksum 校验 | 手机号、信用卡、身份证、邮箱 |
| NER Recognizer | 基于 NLP 模型的命名实体 | 人名、组织、地址、日期 |
| ML/Custom Recognizer | 自定义规则或微调分类器 | 行业特定 PII(病历号、合同编号) |
每个识别器返回一个 RecognizerResult,包含:
entity_type:PII 类型(如PHONE_NUMBER、EMAIL_ADDRESS)score:置信度 0~1-
start / end:在原文中的字符偏移量 -
内置 PII 类型(50+)
常见的有:PERSON、EMAIL_ADDRESS、PHONE_NUMBER、CREDIT_CARD、IBAN_CODE、IP_ADDRESS、LOCATION、DATE_TIME、NRP(国籍/宗教/政治观点)等,并支持多国本地化(中、美、英、德、法等)。
二、Anonymizer Engine — 脱敏操作
检测到 PII 后,Anonymizer 支持五种操作符:
| 操作符 | 说明 |
|---|---|
| Replace | 将 PII 替换为类型占位符,如 <PHONE_NUMBER> |
| Redact | 直接删除 |
| Hash | MD5 / SHA256 / SHA512 单向哈希 |
| Encrypt / Decrypt | AES 128 CBC 可逆加密(用于需要还原的场景) |
| Custom | 传入自定义函数,灵活处理 |
实操一下
# 安装python的依赖
presidio_analyzer==2.2.362
presidio_anonymizer==2.2.362
spacy==3.8.14
spacy-legacy==3.0.12
spacy-loggers==1.0.5
spacy_pkuseg==1.0.1
# zh_core_web_lg==3.8.0 https://github.com/explosion/spacy-models/releases/download/zh_core_web_lg-3.8.0/zh_core_web_lg-3.8.0-py3-none-any.whl
# zh_core_web_sm==3.8.0 https://github.com/explosion/spacy-models/releases/download/zh_core_web_sm-3.8.0/zh_core_web_sm-3.8.0-py3-none-any.whl
## 这两个是模型, wget下来, 然后 pip install xxx.whl
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Presidio + spaCy 中文敏感信息识别与脱敏
安装依赖:
pip install presidio-analyzer presidio-anonymizer spacy
python -m spacy download zh_core_web_lg
"""
from presidio_analyzer import (
AnalyzerEngine, RecognizerResult, EntityRecognizer,
PatternRecognizer, Pattern
)
from presidio_analyzer.nlp_engine import NlpEngineProvider, NlpArtifacts
from presidio_anonymizer import AnonymizerEngine
from presidio_anonymizer.entities import OperatorConfig
from typing import List, Dict, Optional, Tuple
import re
# ══════════════════════════════════════════════════════════════════
# 自定义识别器基类,直接在原始文本上执行正则
# ══════════════════════════════════════════════════════════════════
class RawTextRegexRecognizer(EntityRecognizer):
"""
直接在原始文本字符串上执行正则匹配的识别器。
绕过 Presidio 的 token 机制,解决中文正则失效问题。
"""
def __init__(
self,
entity_type: str,
regex: str,
score: float,
context: List[str],
context_bonus: float = 0.1,
flags: int = re.UNICODE | re.MULTILINE
):
self.entity_type = entity_type
self.pattern = re.compile(regex, flags)
self.base_score = score
self.context_words = [w.lower() for w in context]
self.context_bonus = context_bonus
super().__init__(
supported_entities=[entity_type],
supported_language="zh",
name=f"RawTextRegex_{entity_type}"
)
def load(self):
"""EntityRecognizer 抽象方法,无需实现"""
pass
def analyze(
self,
text: str,
entities: List[str],
nlp_artifacts: NlpArtifacts
) -> List[RecognizerResult]:
"""直接在 text 原始字符串上跑正则"""
if self.entity_type not in entities:
return []
results = []
# 检查上下文(前后 30 字符内是否有关键词)
text_lower = text.lower()
has_context = any(w in text_lower for w in self.context_words)
score = min(self.base_score + self.context_bonus, 1.0) \
if has_context else self.base_score
for match in self.pattern.finditer(text):
results.append(RecognizerResult(
entity_type=self.entity_type,
start=match.start(),
end=match.end(),
score=score
))
return results
# ══════════════════════════════════════════════════════════════════
# 主检测器
# ══════════════════════════════════════════════════════════════════
class ChinesePIIDetector:
"""中文敏感信息检测与脱敏处理器"""
# 实体白名单
ALLOWED_ENTITIES = [
"PERSON", "EMAIL_ADDRESS", "LOCATION", "ORGANIZATION",
"CHINESE_MOBILE", "CHINESE_IDCARD", "CHINESE_BANKCARD",
"CHINESE_PLATE", "CHINESE_ADDRESS", "USCC",
]
# 自定义正则实体(优先级高于 spaCy NER)
CUSTOM_ENTITIES = {
"CHINESE_MOBILE", "CHINESE_IDCARD", "CHINESE_BANKCARD",
"CHINESE_PLATE", "CHINESE_ADDRESS", "USCC",
"EMAIL_ADDRESS", # Presidio 内置邮箱识别器也走原始文本,保留
}
def __init__(self, model_name: str = "zh_core_web_lg"):
self.model_name = model_name
# 初始化 NLP 引擎
nlp_config = {
"nlp_engine_name": "spacy",
"models": [{"lang_code": "zh", "model_name": model_name}]
}
provider = NlpEngineProvider(nlp_configuration=nlp_config)
self.nlp_engine = provider.create_engine()
# 初始化分析引擎
self.analyzer = AnalyzerEngine(
nlp_engine=self.nlp_engine,
supported_languages=["zh"]
)
# 初始化脱敏引擎
self.anonymizer = AnonymizerEngine()
# 注册自定义识别器
self._register_chinese_recognizers()
print(f"[初始化完成] 使用模型: {model_name}")
# ──────────────────────────────────────────────────────────────
# 识别器注册
# ──────────────────────────────────────────────────────────────
def _register_chinese_recognizers(self):
"""注册中文特有识别器(使用 RawTextRegexRecognizer)"""
configs: List[Tuple] = [
# (实体类型, 正则, 置信度, 上下文关键词)
# 1. 手机号(11位,1[3-9]开头)
(
"CHINESE_MOBILE",
r'(?<!\d)1[3-9]\d{9}(?!\d)',
0.85,
["手机", "电话", "联系", "手机号", "电话号码", "联系方式"]
),
# 2. 身份证号(18位)
(
"CHINESE_IDCARD",
r'(?<!\d)[1-9]\d{5}(?:18|19|20)\d{2}(?:0[1-9]|1[0-2])'
r'(?:0[1-9]|[12]\d|3[01])\d{3}[\dXx](?!\d)',
0.85,
["身份证", "身份证号", "证件号"]
),
# 3. 银行卡号(16-19位)
(
"CHINESE_BANKCARD",
r'(?<!\d)(?:4\d{3}|5[1-5]\d{2}|62\d{2}|3[47]\d{2})\d{11,15}(?!\d)',
0.80,
["银行卡", "卡号", "储蓄卡", "信用卡", "借记卡"]
),
# 4. 车牌号(含新能源)
(
"CHINESE_PLATE",
r'[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领]'
r'[A-Z](?:[A-HJ-NP-Z0-9]{5}|[DF][A-HJ-NP-Z0-9]{5}|[A-HJ-NP-Z0-9]{4}[A-HJ-NP-Z0-9])',
0.90,
["车牌", "车牌号", "车辆", "牌照", "号牌"]
),
# 5. 统一社会信用代码(18位)
(
"USCC",
r'(?<![0-9A-Z])[0-9A-HJ-NPQRTUWXY]{2}\d{6}'
r'[0-9A-HJ-NPQRTUWXY]{10}(?![0-9A-Z])',
0.85,
["统一社会信用代码", "营业执照", "信用代码", "注册号"]
),
# 6. 中文地址(省/直辖市开头)
(
"CHINESE_ADDRESS",
r'(?:北京市|天津市|上海市|重庆市|河北省|山西省|辽宁省|吉林省|'
r'黑龙江省|江苏省|浙江省|安徽省|福建省|江西省|山东省|河南省|'
r'湖北省|湖南省|广东省|海南省|四川省|贵州省|云南省|陕西省|'
r'甘肃省|青海省|台湾省|内蒙古自治区|广西壮族自治区|西藏自治区|'
r'宁夏回族自治区|新疆维吾尔自治区|香港特别行政区|澳门特别行政区|'
r'内蒙古|广西|西藏|宁夏|新疆|香港|澳门)'
r'[^\n,,。!?]{5,50}'
r'(?:路|街道|街|巷|弄|号楼|号院|号|栋|单元|室|楼|层|'
r'小区|花园|公寓|大厦|广场|中心|城|里|苑)',
0.80,
["地址", "住址", "居住", "位于", "收货", "寄往", "发货到"]
),
]
for entity, regex, score, context in configs:
recognizer = RawTextRegexRecognizer(
entity_type=entity,
regex=regex,
score=score,
context=context
)
self.analyzer.registry.add_recognizer(recognizer)
# ──────────────────────────────────────────────────────────────
# 结果后处理
# ──────────────────────────────────────────────────────────────
def _filter_results(
self,
results: List[RecognizerResult],
score_threshold: float
) -> List[RecognizerResult]:
"""过滤:置信度阈值 + 实体类型白名单"""
return [
r for r in results
if r.score >= score_threshold
and r.entity_type in self.ALLOWED_ENTITIES
]
def _remove_overlaps(
self,
results: List[RecognizerResult]
) -> List[RecognizerResult]:
"""
去除重叠实体,优先级规则:
1. 置信度越高越优先
2. 同分时自定义正则实体优先(+0.05 bonus)
3. 同优先级时范围越大越优先
"""
def priority(r: RecognizerResult) -> tuple:
bonus = 0.05 if r.entity_type in self.CUSTOM_ENTITIES else 0.0
return (r.score + bonus, r.end - r.start)
sorted_results = sorted(results, key=priority, reverse=True)
kept: List[RecognizerResult] = []
for r in sorted_results:
has_overlap = any(
r.start < k.end and r.end > k.start
for k in kept
)
if not has_overlap:
kept.append(r)
return sorted(kept, key=lambda x: x.start)
# ──────────────────────────────────────────────────────────────
# 核心接口
# ──────────────────────────────────────────────────────────────
def analyze(
self,
text: str,
language: str = "zh",
score_threshold: float = 0.6
) -> List[RecognizerResult]:
"""
分析文本中的敏感信息
Args:
text: 待分析文本
language: 语言代码
score_threshold: 置信度过滤阈值
Returns:
去重过滤后的识别结果列表
"""
raw_results = self.analyzer.analyze(
text=text,
language=language,
entities=self.ALLOWED_ENTITIES,
return_decision_process=False
)
filtered = self._filter_results(raw_results, score_threshold)
return self._remove_overlaps(filtered)
def anonymize(
self,
text: str,
operators: Optional[Dict[str, OperatorConfig]] = None,
language: str = "zh",
score_threshold: float = 0.6,
verbose: bool = False
) -> Dict:
"""
对文本进行脱敏处理
Args:
text: 待脱敏文本
operators: 自定义脱敏规则(覆盖默认规则)
language: 语言代码
score_threshold: 置信度过滤阈值
verbose: 是否打印详细结果
Returns:
{original, anonymized, entities, has_pii, entity_count}
"""
analyzer_results = self.analyze(text, language, score_threshold)
if not analyzer_results:
result_dict = {
"original": text,
"anonymized": text,
"entities": [],
"has_pii": False,
"entity_count": 0
}
if verbose:
self._print_result(result_dict)
return result_dict
# 默认脱敏规则
default_operators: Dict[str, OperatorConfig] = {
"PERSON": OperatorConfig("replace", {"new_value": "<姓名>"}),
"EMAIL_ADDRESS": OperatorConfig("mask", {"masking_char": "*",
"chars_to_mask": 4,
"from_end": False}),
"LOCATION": OperatorConfig("replace", {"new_value": "<地点>"}),
"ORGANIZATION": OperatorConfig("replace", {"new_value": "<机构>"}),
"CHINESE_MOBILE": OperatorConfig("mask", {"masking_char": "*",
"chars_to_mask": 4,
"from_end": True}),
"CHINESE_IDCARD": OperatorConfig("mask", {"masking_char": "*",
"chars_to_mask": 12,
"from_end": False}),
"CHINESE_BANKCARD": OperatorConfig("mask", {"masking_char": "*",
"chars_to_mask": 8,
"from_end": True}),
"CHINESE_PLATE": OperatorConfig("replace", {"new_value": "<车牌>"}),
"CHINESE_ADDRESS": OperatorConfig("mask", {"masking_char": "*",
"chars_to_mask": 15,
"from_end": False}),
"USCC": OperatorConfig("mask", {"masking_char": "*",
"chars_to_mask": 10,
"from_end": True}),
}
if operators:
default_operators.update(operators)
# 只保留实际识别到的实体类型
active_operators = {
et: op for et, op in default_operators.items()
if any(r.entity_type == et for r in analyzer_results)
}
anonymized_result = self.anonymizer.anonymize(
text=text,
analyzer_results=analyzer_results,
operators=active_operators
)
entities_info = [
{
"type": r.entity_type,
"text": text[r.start:r.end],
"start": r.start,
"end": r.end,
"score": round(r.score, 3),
}
for r in analyzer_results
]
result_dict = {
"original": text,
"anonymized": anonymized_result.text,
"entities": entities_info,
"has_pii": True,
"entity_count": len(entities_info)
}
if verbose:
self._print_result(result_dict)
return result_dict
# ──────────────────────────────────────────────────────────────
# 工具方法
# ──────────────────────────────────────────────────────────────
def _print_result(self, result: Dict):
"""格式化打印脱敏结果"""
print("\n" + "=" * 70)
print("原始文本:")
print(f" {result['original']}")
print(f"\n脱敏后文本 ({result['entity_count']} 处敏感信息):")
print(f" {result['anonymized']}")
if result["entities"]:
print("\n识别详情:")
for e in result["entities"]:
print(f" • [{e['type']}] \"{e['text']}\" "
f"(位置:{e['start']}-{e['end']}, 置信度:{e['score']})")
print("=" * 70)
def batch_process(self, texts: List[str], **kwargs) -> List[Dict]:
"""批量处理文本"""
return [self.anonymize(text, **kwargs) for text in texts]
def get_supported_entities(self) -> List[str]:
"""获取支持的实体类型列表"""
return self.analyzer.get_supported_entities()
# ══════════════════════════════════════════════════════════════════
# 演示入口
# ══════════════════════════════════════════════════════════════════
def demo():
print("初始化中文 PII 检测器...")
print("首次运行请先执行: python -m spacy download zh_core_web_lg\n")
detector = ChinesePIIDetector(model_name="zh_core_web_lg")
supported = detector.get_supported_entities()
print(f"\n支持的实体类型 ({len(supported)} 种):")
for entity in sorted(supported):
print(f" • {entity}")
# ── 标准测试用例 ──────────────────────────────────────────────
test_cases = [
# 用例1:综合信息
(
"联系人:张三,手机号:13800138000,身份证号:110101199001011234,"
"邮箱:zhangsan@example.com,地址:北京市海淀区中关村大街1号科技大厦1001室,"
"银行卡:6222021234567890123,车牌:京A88888,"
"统一社会信用代码:91110108MA00123456"
),
# 用例2:电商场景
(
"客服:您好,请问是李女士吗?您的订单已发货到"
"上海市浦东新区陆家嘴环路1000号恒生银行大厦,"
"收货人电话是13912345678,如有问题请联系客服。"
),
# 用例3:社交场景
(
"姓名:王五,电话:18666668888,"
"现居:广东省深圳市南山区科技园南区腾讯大厦,"
"身份证号:440304198505152345,邮箱:wangwu@163.com,曾在阿里巴巴工作"
),
# 用例4:医疗场景
(
"患者:赵六,男,1988年生,联系电话15011112222,"
"住址:浙江省杭州市西湖区文三路500号,"
"身份证号:330106198801011111,就诊于浙江大学医学院附属第一医院"
),
# 用例5:企业信息
(
"公司名称:北京科技有限公司,统一社会信用代码:91110105MA0054321E,"
"法定代表人:陈明,注册地址:北京市朝阳区建国路88号,联系电话:010-12345678"
),
]
print("\n" + "=" * 70)
print("开始测试中文敏感信息识别与脱敏")
print("=" * 70)
for i, text in enumerate(test_cases, 1):
print(f"\n[测试用例 {i}/{len(test_cases)}]")
detector.anonymize(text, verbose=True)
# ── 自定义脱敏规则演示 ────────────────────────────────────────
print("\n\n[自定义脱敏规则演示]")
print("-" * 70)
custom_text = (
"紧急联系人:陈经理,手机:13500001111,"
"身份证:500101199510105678,车牌:沪B66666"
)
custom_operators = {
"CHINESE_MOBILE": OperatorConfig("mask", {
"masking_char": "*", "chars_to_mask": 8, "from_end": True
}),
"CHINESE_IDCARD": OperatorConfig("replace", {
"new_value": "<身份证已隐藏>"
}),
"PERSON": OperatorConfig("replace", {
"new_value": "<联系人>"
}),
"CHINESE_PLATE": OperatorConfig("mask", {
"masking_char": "*", "chars_to_mask": 4, "from_end": True
}),
}
print(f"原文: {custom_text}")
print("规则: 手机号保留前3位 | 身份证完全替换 | 车牌保留前2位")
detector.anonymize(custom_text, operators=custom_operators, verbose=True)
# ── 批量处理演示 ──────────────────────────────────────────────
print("\n\n[批量处理演示]")
print("-" * 70)
batch_texts = [
"用户A,电话13900139000,住北京市海淀区中关村大街1号科技大厦",
"用户B,电话13800138000,住上海市浦东新区陆家嘴环路1000号大厦",
"用户C,电话13700137000,住广东省深圳市南山区科技园南区大厦",
]
batch_results = detector.batch_process(batch_texts)
print(f"共处理 {len(batch_results)} 条记录:")
for i, res in enumerate(batch_results, 1):
print(f" {i}. [发现{res['entity_count']}处PII] {res['anonymized']}")
print("\n[演示完成]")
if __name__ == "__main__":
demo()
[测试用例 1/5]
======================================================================
原始文本:
联系人:张三,手机号:13800138000,身份证号:110101199001011234,邮箱:zhangsan@example.com,地址:北京市海淀区中关村大街1号科技大厦1001室,银行卡:6222021234567890123,车牌:京A88888,统一社会信用代码:91110108MA00123456
脱敏后文本 (8 处敏感信息):
联系人:<姓名>,手机号:1380013****,身份证号:************011234,邮箱:****gsan@example.com,地址:***************大厦1001室,银行卡:62220212345********,车牌:<车牌>,统一社会信用代码:91110108**********
识别详情:
• [PERSON] "张三" (位置:4-6, 置信度:0.85)
• [CHINESE_MOBILE] "13800138000" (位置:11-22, 置信度:0.95)
• [CHINESE_IDCARD] "110101199001011234" (位置:28-46, 置信度:0.95)
• [EMAIL_ADDRESS] "zhangsan@example.com" (位置:50-70, 置信度:1.0)
• [CHINESE_ADDRESS] "北京市海淀区中关村大街1号科技大厦1001室" (位置:74-96, 置信度:0.9)
• [CHINESE_BANKCARD] "6222021234567890123" (位置:101-120, 置信度:0.9)
• [CHINESE_PLATE] "京A88888" (位置:124-131, 置信度:1.0)
• [USCC] "91110108MA00123456" (位置:141-159, 置信度:0.95)
======================================================================
[测试用例 2/5]
======================================================================
原始文本:
客服:您好,请问是李女士吗?您的订单已发货到上海市浦东新区陆家嘴环路1000号恒生银行大厦,收货人电话是13912345678,如有问题请联系客服。
脱敏后文本 (3 处敏感信息):
客服:您好,请问是<姓名>吗?您的订单已发货到***************0号恒生银行大厦,收货人电话是1391234****,如有问题请联系客服。
识别详情:
• [PERSON] "李女士" (位置:9-12, 置信度:0.85)
• [CHINESE_ADDRESS] "上海市浦东新区陆家嘴环路1000号恒生银行大厦" (位置:22-45, 置信度:0.9)
• [CHINESE_MOBILE] "13912345678" (位置:52-63, 置信度:0.95)
======================================================================
[测试用例 3/5]
======================================================================
原始文本:
姓名:王五,电话:18666668888,现居:广东省深圳市南山区科技园南区腾讯大厦,身份证号:440304198505152345,邮箱:wangwu@163.com,曾在阿里巴巴工作
脱敏后文本 (6 处敏感信息):
姓名:<姓名>,电话:1866666****,现居:***************讯大厦,身份证号:************152345,邮箱:****wu@163.com,曾在<机构>工作
识别详情:
• [PERSON] "王五" (位置:3-5, 置信度:0.85)
• [CHINESE_MOBILE] "18666668888" (位置:9-20, 置信度:0.95)
• [CHINESE_ADDRESS] "广东省深圳市南山区科技园南区腾讯大厦" (位置:24-42, 置信度:0.8)
• [CHINESE_IDCARD] "440304198505152345" (位置:48-66, 置信度:0.95)
• [EMAIL_ADDRESS] "wangwu@163.com" (位置:70-84, 置信度:1.0)
• [ORGANIZATION] "阿里巴巴" (位置:87-91, 置信度:0.85)
======================================================================
[测试用例 4/5]
======================================================================
原始文本:
患者:赵六,男,1988年生,联系电话15011112222,住址:浙江省杭州市西湖区文三路500号,身份证号:330106198801011111,就诊于浙江大学医学院附属第一医院
脱敏后文本 (5 处敏感信息):
患者:<姓名>,男,1988年生,联系电话1501111****,住址:***************号,身份证号:************011111,就诊于<机构>
识别详情:
• [PERSON] "赵六" (位置:3-5, 置信度:0.85)
• [CHINESE_MOBILE] "15011112222" (位置:19-30, 置信度:0.95)
• [CHINESE_ADDRESS] "浙江省杭州市西湖区文三路500号" (位置:34-50, 置信度:0.9)
• [CHINESE_IDCARD] "330106198801011111" (位置:56-74, 置信度:0.95)
• [ORGANIZATION] "浙江大学医学院附属第一医院" (位置:78-91, 置信度:0.85)
======================================================================
[测试用例 5/5]
======================================================================
原始文本:
公司名称:北京科技有限公司,统一社会信用代码:91110105MA0054321E,法定代表人:陈明,注册地址:北京市朝阳区建国路88号,联系电话:010-12345678
脱敏后文本 (4 处敏感信息):
公司名称:<机构>,统一社会信用代码:91110105**********,法定代表人:<姓名>,注册地址:************,联系电话:010-12345678
识别详情:
• [ORGANIZATION] "北京科技有限公司" (位置:5-13, 置信度:0.85)
• [USCC] "91110105MA0054321E" (位置:23-41, 置信度:0.95)
• [PERSON] "陈明" (位置:48-50, 置信度:0.85)
• [CHINESE_ADDRESS] "北京市朝阳区建国路88号" (位置:56-68, 置信度:0.9)
======================================================================
[自定义脱敏规则演示]
----------------------------------------------------------------------
原文: 紧急联系人:陈经理,手机:13500001111,身份证:500101199510105678,车牌:沪B66666
规则: 手机号保留前3位 | 身份证完全替换 | 车牌保留前2位
======================================================================
原始文本:
紧急联系人:陈经理,手机:13500001111,身份证:500101199510105678,车牌:沪B66666
脱敏后文本 (4 处敏感信息):
紧急联系人:<联系人>,手机:135********,身份证:<身份证已隐藏>,车牌:沪B6****
识别详情:
• [PERSON] "陈经理" (位置:6-9, 置信度:0.85)
• [CHINESE_MOBILE] "13500001111" (位置:13-24, 置信度:0.95)
• [CHINESE_IDCARD] "500101199510105678" (位置:29-47, 置信度:0.95)
• [CHINESE_PLATE] "沪B66666" (位置:51-58, 置信度:1.0)
======================================================================
[批量处理演示]
----------------------------------------------------------------------
共处理 3 条记录:
1. [发现2处PII] 用户A,电话1390013****,住***************大厦
2. [发现2处PII] 用户B,电话1380013****,住***************0号大厦
3. [发现2处PII] 用户C,电话1370013****,住***************厦
总结, Presidio + spaCy 基于 CNN(卷积神经网络)的架构, 对GPU 不敏感, 即使上了GPU ,占用一般低于5% ,我们线上部署采用CPU + 多进程模式部署, 效果良好, Presidio + spaCy + Fastapi 单机压测 QPS 大概可以跑到 150多, 全文完。